{
"_id": 1,
"first_name": "Tom",
"email": "tom@example.com",
"cell": "765-555-5555",
"likes": [
"fashion",
"spas",
"shopping"
],
"businesses": [
{
"name": "Entertainment 1080",
"partner": "Jean",
"status": "Bankrupt",
"date_founded": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"name": "Swag for Tweens",
"date_founded": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}Doing Data Analytics Using NOSQL
Introduction to MongoDB
Databases
Data analytics
MongoDB
NoSQL
MongoDB Database
MongoDB in Summary
Note
- It is a General purpose
Documentdatabase - structures data in documents similar to json Objects
- A bit different from how relational databases ,structures data in
tablesofrowsandcolumns - Provides drivers in all major programming languages
- Allows flexibility of using one format for any application and thus making development easier and speeds up productivity
What is a document model
A document database (also known as a document-oriented database or a document store) is a database that stores information in documents. Document databases offer a variety of advantages, including:
Note
- An intuitive data model that is fast and easy for developers to work with
- A flexible schema that allows for the data model to evolve as application needs change
- The ability to horizontally scale out Because of these advantages, document databases are general-purpose databases that can be used in a variety of use cases and industries.
Document databases are considered to be non-relational (or NoSQL) databases. Instead of storing data in fixed rows and columns, document databases use flexible documents. Document databases are the most popular alternative to tabular, relational databases. Learn more about NoSQL databases.
What are documents?
Note
A document is a record in a document database. A document typically stores information about one object and any of its related metadata. Documents store data in field-value pairs. The values can be a variety of types and structures, including strings, numbers, dates, arrays, or objects. Documents can be stored in formats like JSON, BSON, and XML.
Below is a JSON document that stores information about a user named Tom.
Collections
Note
A collection is a group of documents. Collections typically store documents that have similar contents. Not all documents in a collection are required to have the same fields, because document databases have flexible schemas. Note that some document databases provide schema validation, so the schema can optionally be locked down when needed.
Continuing with the example above, the document with information about Tom could be stored in a collection named users. More documents could be added to the users collection in order to store information about other users. For example, the document below that stores information about Donna could be added to the users collection.
{
"_id": 2,
"first_name": "Donna",
"email": "donna@example.com",
"spouse": "Joe",
"likes": [
"spas",
"shopping",
"live tweeting"
],
"businesses": [
{
"name": "Castle Realty",
"status": "Thriving",
"date_founded": {
"$date": "2013-11-21T04:00:00Z"
}
}
]
}CRUD operations
Document databases typically have an API or query language that allows developers to execute the CRUD (create, read, update, and delete) operations.
Note
-
Create:Documents can be created in the database. Each document has a unique identifier. -
Read :Documents can be read from the database. The API or query language allows developers to query for documents using their unique identifiers or field values. Indexes can be added to the database in order to increase read performance. -
Update:Existing documents can be updated — either in whole or in part. -
Delete:Documents can be deleted from the database.
What are the key features of document databases?
Document databases have the following key features:
Note
-
Document model:Data is stored in documents (unlike other databases that store data in structures like tables or graphs). Documents map to objects in most popular programming languages, which allows developers to rapidly develop their applications. +Flexible schema:Document databases have flexible schemas, meaning that not all documents in a collection need to have the same fields. Note that some document databases support schema validation, so the schema can be optionally locked down. -
Distributed and resilient:Document databases are distributed, which allows for horizontal scaling (typically cheaper than vertical scaling) and data distribution. Document databases provide resiliency through replication. -
Querying through an API or query language:Document databases have an API or query language that allows developers to execute the CRUD operations on the database. Developers have the ability to query for documents based on unique identifiers or field values.
What makes document databases different from relational databases?
Three key factors differentiate document databases from relational databases:
Note
- The intuitiveness of the data model: Documents map to the objects in code, so they are much more natural to work with. There is no need to decompose data across tables, run expensive joins, or integrate a separate Object Relational Mapping (ORM) layer. Data that is accessed together is stored together, so developers have less code to write and end users get higher performance.
- The ubiquity of JSON documents: JSON has become an established standard for data interchange and storage. JSON documents are lightweight, language-independent, and human-readable. Documents are a superset of all other data models so developers can structure data in the way their applications need — rich objects, key-value pairs, tables, geospatial and time-series data, or the nodes and edges of a graph.
- The flexibility of the schema: A document’s schema is dynamic and self-describing, so developers don’t need to first pre-define it in the database. Fields can vary from document to document. Developers can modify the structure at any time, avoiding disruptive schema migrations. Some document databases offer schema validation so you can optionally enforce rules governing document structures.
{
"_id": 1,
"first_name": "Tom",
"email": "tom@example.com",
"cell": "765-555-5555",
"likes": [
"fashion",
"spas",
"shopping"
],
"businesses": [
{
"name": "Entertainment 1080",
"partner": "Jean",
"status": "Bankrupt",
"date_founded": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"name": "Swag for Tweens",
"date_founded": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}All of the information about Tom is stored in a single document.
Now let’s consider how we can store that same information in a relational database. We’ll begin by creating a table that stores the basic information about the user.
| ID | First name | cell | |
|---|---|---|---|
| 1 | Tom | Tom@example.com | 555-555-555 |
A user can like many things (meaning there is a one-to-many relationship between a user and likes), so we will create a new table named “Likes” to store a user’s likes. The Likes table will have a foreign key that references the ID column in the Users table.
| ID | User_Id | like |
|---|---|---|
| 10 | 1 | Fashion |
| 11 | 1 | Spars |
| 12 | 1 | Shopping |
| ID | User_ID | Name | Partner | status | date_founded |
|---|---|---|---|---|---|
| 20 | 1 | entertainment | Jean | Bankrupt | 2011-05-19 |
| 21 | 1 | swag | NULL | NULL | 2011-06-12 |
In this simple example, we see that data about a user could be stored in a single document in a document database or three tables in a relational database. When a developer wants to retrieve or update information about a user in the document database, they can write one query with zero joins. Interacting with the database is straightforward, and modeling the data in the database is intuitive.
Mapping Terms and Concepts from SQL to MongoDB
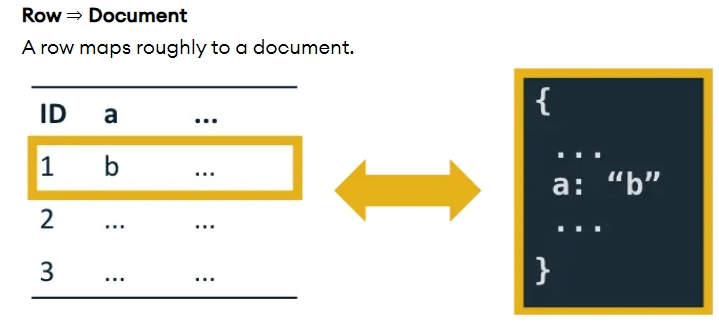
Row => Document
Column => Field

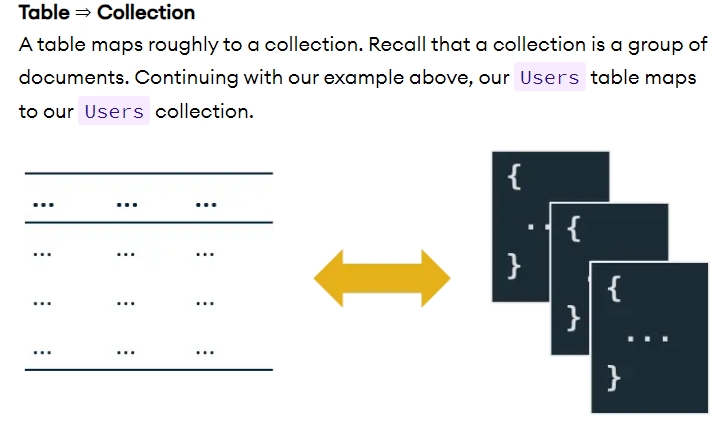
Table => Collection
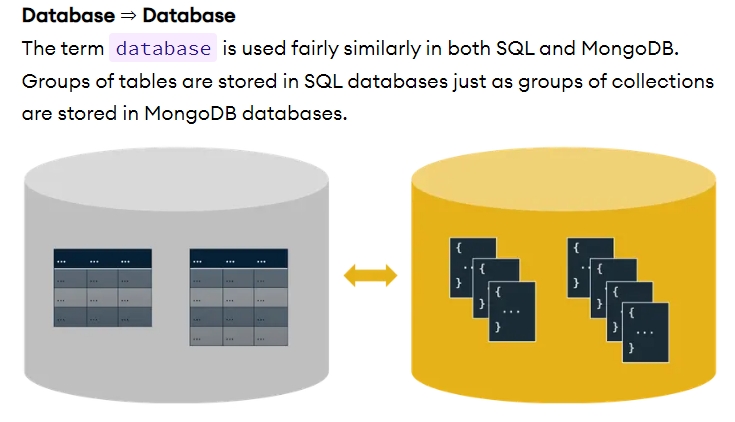
Database=>Database
knitr::include_graphics("compare6.jpeg")
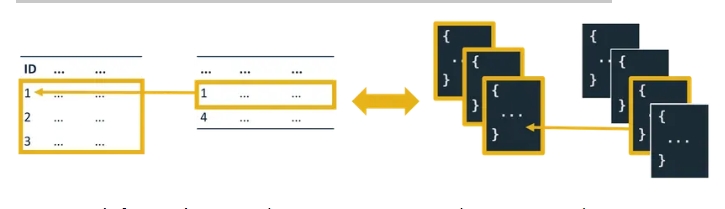
Left Outer Join ⇒ $lookup (Aggregation Pipeline)
When you need to pull all of the information from one table and join it with any matching information in a second table, you can use a left outer join in SQL. MongoDB has a stage similar to a left outer join that you can use with the aggregation framework. For those not familiar with the aggregation framework, it allows you to analyze your data in real-time. Using the framework, you can create an aggregation pipeline that consists of one or more stages. Each stage transforms the documents and passes the output to the next stage. $lookup is an aggregation framework stage that allows you to perform a left outer join to an unsharded collection in the same database.
What are the relationships between document databases and other databases?
The document model is a superset of other data models, including key-value pairs, relational, objects, graph, and geospatial.
Note
- Key-value pairs can be modeled with fields and values in a document. Any field in a document can be indexed, providing developers with additional flexibility in querying the data.
- Relational data can be modeled differently (and some would argue more intuitively) by keeping related data together in a single document using embedded documents and arrays. Related data can also be stored in separate documents, and database references can be used to connect the related data.
- Documents map to objects in most popular programming languages.
- Graph nodes and/or edges can be modeled as documents. Edges can also be modeled through database references. Graph queries can be run using operations like $graphLookup.
- Geospatial data can be modeled as arrays in documents.
Working with MongoDB Syntax in R and Compass
Note
- install and load
mongolitepackage
- Connect to a connection string
connection_string = "mongodb+srv://myAtlasDBUser:mosesDowart@myatlasclusteredu.ywdjesc.mongodb.net/?retryWrites=true&w=majority&appName=myAtlasClusterEDU"
trips_collection = mongo(collection="trips", db="sample_training", url=connection_string)insecting documents to a collection
insertOne()
Insert a Single Document Use insertOne() to insert a document into a collection. Within the parentheses of insertOne(), include an object that contains the document data. The syntax is as follows
db.<collection>.insertOne()- if we wanted to insert a document to a collection called
gradeswe would go ahead and write
db.grades.insertOne()mongoDB automatically creates a database for you if it does not exist
Here’s an example:
db.grades.insertOne({
student_id: 654321,
products: [
{
type: "exam",
score: 90,
},
{
type: "homework",
score: 59,
},
{
type: "quiz",
score: 75,
},
{
type: "homework",
score: 88,
},
],
class_id: 550,
})insertMany()
Insert Multiple Documents Use insertMany() to insert multiple documents at once. Within insertMany(), include the documents within an array. Each document should be separated by a comma. the syntax is as follows , an array of documents .
db.<collection>.insertMany([
<collection 1>,
<collection 2>,
......
])Here’s an example:
db.grades.insertMany([
{
student_id: 546789,
products: [
{
type: "quiz",
score: 50,
},
{
type: "homework",
score: 70,
},
{
type: "quiz",
score: 66,
},
{
type: "exam",
score: 70,
},
],
class_id: 551,
},
{
student_id: 777777,
products: [
{
type: "exam",
score: 83,
},
{
type: "quiz",
score: 59,
},
{
type: "quiz",
score: 72,
},
{
type: "quiz",
score: 67,
},
],
class_id: 550,
},
{
student_id: 223344,
products: [
{
type: "exam",
score: 45,
},
{
type: "homework",
score: 39,
},
{
type: "quiz",
score: 40,
},
{
type: "homework",
score: 88,
},
],
class_id: 551,
},
])Finding documents in MongoDB
- the syntax for finding documents is given by :
db.<collection>.find()similar SQL query would be :
SELECT * FROM collection;Retrieving a specific document from our collection
$eq Stands for Equal
{field : {$eq : <value>}}
{field : <value>}Find a Document with Equality When given equality with an _id field, the find() command will return the specified document that matches the _id. Here’s an example:
db.zips.find({ _id: ObjectId("5c8eccc1caa187d17ca6ed16") })Find Documents with an Array That Contains a Specified Value In the following example, “InvestmentFund” is not enclosed in square brackets, so MongoDB returns all documents within the products array that contain the specified value.
db.accounts.find({ products: "InvestmentFund"})a similar query in
SQLwould be :
SELECT * FROM accounts WHERE products = "InvestmentFund";In R
Get all the rows in Mongolite
trips_collection$find()Get a few rows with limit
trips_collection$find(limit = 5)
#> tripduration start station id start station name end station id
#> 1 589 489 10 Ave & W 28 St 284
#> 2 1770 3226 W 82 St & Central Park West 509
#> 3 694 268 Howard St & Centre St 497
#> 4 1376 527 E 33 St & 2 Ave 259
#> 5 280 512 W 29 St & 9 Ave 466
#> end station name bikeid usertype birth year
#> 1 Greenwich Ave & 8 Ave 21997 Subscriber 1982
#> 2 9 Ave & W 22 St 22541 Subscriber 1970
#> 3 E 17 St & Broadway 15747 Subscriber 1996
#> 4 South St & Whitehall St 23933 Subscriber 1963
#> 5 W 25 St & 6 Ave 23144 Subscriber 1988
#> start station location.type start station location.coordinates
#> 1 Point -74.00177, 40.75066
#> 2 Point -73.97137, 40.78275
#> 3 Point -73.99973, 40.71911
#> 4 Point -73.97606, 40.74402
#> 5 Point -73.99839, 40.75007
#> end station location.type end station location.coordinates
#> 1 Point -74.00264, 40.73902
#> 2 Point -74.00197, 40.74550
#> 3 Point -73.99009, 40.73705
#> 4 Point -74.01234, 40.70122
#> 5 Point -73.99145, 40.74395
#> start time stop time
#> 1 2016-01-01 02:00:48 2016-01-01 02:10:37
#> 2 2016-01-01 02:04:43 2016-01-01 02:34:14
#> 3 2016-01-01 02:02:18 2016-01-01 02:13:53
#> 4 2016-01-01 02:03:12 2016-01-01 02:26:09
#> 5 2016-01-01 02:10:29 2016-01-01 02:15:09get all rows where tripduration is 1770
trips_collection$find('{"tripduration": 1770}')
#> tripduration start station id start station name end station id
#> 1 1770 3226 W 82 St & Central Park West 509
#> 2 1770 2006 Central Park S & 6 Ave 3165
#> end station name bikeid usertype birth year
#> 1 9 Ave & W 22 St 22541 Subscriber 1970
#> 2 Central Park West & W 72 St 19570 Customer
#> start station location.type start station location.coordinates
#> 1 Point -73.97137, 40.78275
#> 2 Point -73.97634, 40.76591
#> end station location.type end station location.coordinates
#> 1 Point -74.00197, 40.74550
#> 2 Point -73.97621, 40.77579
#> start time stop time
#> 1 2016-01-01 02:04:43 2016-01-01 02:34:14
#> 2 2016-01-01 12:59:01 2016-01-01 13:28:31get all rows where usertype is
Customer
trips_collection$find('{"usertype": "Customer"}')#> _id usertype
#> 1 572bb8222b288919b68abfaa Customer
#> 2 572bb8222b288919b68abfdd Customer
#> 3 572bb8222b288919b68ac031 Customer
#> 4 572bb8222b288919b68ac073 Customer
#> 5 572bb8222b288919b68ac0e9 Customer
$in Operator
Find a Document by Using the $in Operator Use the $in operator to select documents where the value of a field equals any value in the specified array. The syntax is given by
db.<collection>.find({
<field>:{$in: [<value>,<value2>,....]}
})Here’s an example:
db.zips.find({ tripduration: { $in: [1770, 1376] } })$nin
$nin stands for Not In.
Find restaurants not in these three shop ranks 1, 3, 5 .
db.restaurants.find(
{
cuisine: {
$nin: ["American", "Irish", "Bakery"]
}
}
)In R
trips_collection$find('{"tripduration": {"$in" : [1770,1376]}}')
#> tripduration start station id start station name end station id
#> 1 1770 3226 W 82 St & Central Park West 509
#> 2 1376 527 E 33 St & 2 Ave 259
#> 3 1770 2006 Central Park S & 6 Ave 3165
#> end station name bikeid usertype birth year
#> 1 9 Ave & W 22 St 22541 Subscriber 1970
#> 2 South St & Whitehall St 23933 Subscriber 1963
#> 3 Central Park West & W 72 St 19570 Customer
#> start station location.type start station location.coordinates
#> 1 Point -73.97137, 40.78275
#> 2 Point -73.97606, 40.74402
#> 3 Point -73.97634, 40.76591
#> end station location.type end station location.coordinates
#> 1 Point -74.00197, 40.74550
#> 2 Point -74.01234, 40.70122
#> 3 Point -73.97621, 40.77579
#> start time stop time
#> 1 2016-01-01 02:04:43 2016-01-01 02:34:14
#> 2 2016-01-01 02:03:12 2016-01-01 02:26:09
#> 3 2016-01-01 12:59:01 2016-01-01 13:28:31Comparison Operators
Finding Documents by Using Comparison Operators Review the following comparison operators:
$gt,$lt,$lte, and$gte$gt: Use the$gtoperator to match documents with a field greater than the given value. For example:
db.sales.find({ "tripduration": { $gt: 3244}})In R
trips_collection$find('{"tripduration": {"$gt" : 3244}}',limit = 5)
#> tripduration start station id start station name end station id
#> 1 7881 479 9 Ave & W 45 St 267
#> 2 49253 463 9 Ave & W 16 St 476
#> 3 11334 479 9 Ave & W 45 St 267
#> 4 11960 529 W 42 St & 8 Ave 486
#> 5 35248 250 Lafayette St & Jersey St 252
#> end station name bikeid usertype birth year
#> 1 Broadway & W 36 St 16515 Customer
#> 2 E 31 St & 3 Ave 23753 Customer
#> 3 Broadway & W 36 St 16177 Customer
#> 4 Broadway & W 29 St 23826 Customer
#> 5 MacDougal St & Washington Sq 21228 Customer
#> start station location.type start station location.coordinates
#> 1 Point -73.99126, 40.76019
#> 2 Point -74.00443, 40.74207
#> 3 Point -73.99126, 40.76019
#> 4 Point -73.99099, 40.75757
#> 5 Point -73.99565, 40.72456
#> end station location.type end station location.coordinates
#> 1 Point -73.98765, 40.75098
#> 2 Point -73.97966, 40.74394
#> 3 Point -73.98765, 40.75098
#> 4 Point -73.98856, 40.74620
#> 5 Point -73.99852, 40.73226
#> start time stop time
#> 1 2016-01-01 03:10:50 2016-01-01 05:22:11
#> 2 2016-01-01 03:20:04 2016-01-01 17:00:57
#> 3 2016-01-01 03:09:38 2016-01-01 06:18:33
#> 4 2016-01-01 03:11:43 2016-01-01 06:31:04
#> 5 2016-01-01 03:11:46 2016-01-01 12:59:14-
$ltUse the$ltoperator to match documents with a field less than the given value. For example:
db.sales.find({ "tripduration": { $lt: 100}})In R
trips_collection$find('{"tripduration": {"$lt" : 100}}',limit = 5)
#> tripduration start station id start station name end station id
#> 1 89 483 E 12 St & 3 Ave 237
#> 2 83 3119 Vernon Blvd & 50 Ave 3122
#> 3 79 395 Bond St & Schermerhorn St 395
#> 4 72 79 Franklin St & W Broadway 249
#> 5 85 307 Canal St & Rutgers St 340
#> end station name bikeid usertype birth year
#> 1 E 11 St & 2 Ave 19374 Subscriber 1971
#> 2 48 Ave & 5 St 24257 Subscriber 1990
#> 3 Bond St & Schermerhorn St 24277 Subscriber 1986
#> 4 Harrison St & Hudson St 15318 Subscriber 1981
#> 5 Madison St & Clinton St 18713 Subscriber 1992
#> start station location.type start station location.coordinates
#> 1 Point -73.98890, 40.73223
#> 2 Point -73.95412, 40.74233
#> 3 Point -73.98411, 40.68807
#> 4 Point -74.00667, 40.71912
#> 5 Point -73.98990, 40.71427
#> end station location.type end station location.coordinates
#> 1 Point -73.98672, 40.73047
#> 2 Point -73.95587, 40.74436
#> 3 Point -73.98411, 40.68807
#> 4 Point -74.00900, 40.71871
#> 5 Point -73.98776, 40.71269
#> start time stop time
#> 1 2016-01-01 02:28:07 2016-01-01 02:29:36
#> 2 2016-01-01 03:11:29 2016-01-01 03:12:53
#> 3 2016-01-01 03:10:26 2016-01-01 03:11:46
#> 4 2016-01-01 04:25:25 2016-01-01 04:26:37
#> 5 2016-01-01 03:58:21 2016-01-01 03:59:47-
$lte: Use the$lteoperator to match documents with a field less than or equal to the given value. For example:
db.sales.find({ "customer.age": { $lte: 65}})-
$gte: Use the$gteoperator to match documents with a field greater than or equal to the given value. For example:
db.sales.find({ "customer.age": { $gte: 65}})$elemMatch
Find a Document by Using the $elemMatch Operator Use the $elemMatch operator to find all documents that contain the specified subdocument. For example:
db.sales.find({
items: {
$elemMatch: { name: "laptop", price: { $gt: 800 }, quantity: { $gte: 1 } },
},
})$ne
$ne stands for Not Equal.
find restaurants with grades not equal to “A”.
db.restaurants.find(
{
grades: {
$elemMatch: {
grade: {
$ne: "A"
}
}
}
}
)And , or
Finding Documents by Using Logical Operators Review the following logical operators: implicit $and, $or.
db.routes.find({ "usertype": "Subscriber", tripduration: { $lt: 100 } })similar SQL query would be
SELECT * FROM routes WHERE usertype = "Subscriber" AND tripduration < 23;db.routes.find({
$or: [{ dst_airport: "SEA" }, { src_airport: "SEA" }],
})trips_collection$find('{"tripduration": {"$lt" : 100},"usertype":"Subscriber"}',limit = 5)
#> tripduration start station id start station name end station id
#> 1 89 483 E 12 St & 3 Ave 237
#> 2 83 3119 Vernon Blvd & 50 Ave 3122
#> 3 79 395 Bond St & Schermerhorn St 395
#> 4 72 79 Franklin St & W Broadway 249
#> 5 85 307 Canal St & Rutgers St 340
#> end station name bikeid usertype birth year
#> 1 E 11 St & 2 Ave 19374 Subscriber 1971
#> 2 48 Ave & 5 St 24257 Subscriber 1990
#> 3 Bond St & Schermerhorn St 24277 Subscriber 1986
#> 4 Harrison St & Hudson St 15318 Subscriber 1981
#> 5 Madison St & Clinton St 18713 Subscriber 1992
#> start station location.type start station location.coordinates
#> 1 Point -73.98890, 40.73223
#> 2 Point -73.95412, 40.74233
#> 3 Point -73.98411, 40.68807
#> 4 Point -74.00667, 40.71912
#> 5 Point -73.98990, 40.71427
#> end station location.type end station location.coordinates
#> 1 Point -73.98672, 40.73047
#> 2 Point -73.95587, 40.74436
#> 3 Point -73.98411, 40.68807
#> 4 Point -74.00900, 40.71871
#> 5 Point -73.98776, 40.71269
#> start time stop time
#> 1 2016-01-01 02:28:07 2016-01-01 02:29:36
#> 2 2016-01-01 03:11:29 2016-01-01 03:12:53
#> 3 2016-01-01 03:10:26 2016-01-01 03:11:46
#> 4 2016-01-01 04:25:25 2016-01-01 04:26:37
#> 5 2016-01-01 03:58:21 2016-01-01 03:59:47Find a Document by Using the $or Operator Use the $or operator to select documents that match at least one of the included expressions. For example:
trips_collection$find('{"$or": [{"tripduration": {"$lt": 100}}, {"usertype": "Subscriber"}]}',limit = 5)
#> tripduration start station id start station name end station id
#> 1 589 489 10 Ave & W 28 St 284
#> 2 1770 3226 W 82 St & Central Park West 509
#> 3 694 268 Howard St & Centre St 497
#> 4 1376 527 E 33 St & 2 Ave 259
#> 5 280 512 W 29 St & 9 Ave 466
#> end station name bikeid usertype birth year
#> 1 Greenwich Ave & 8 Ave 21997 Subscriber 1982
#> 2 9 Ave & W 22 St 22541 Subscriber 1970
#> 3 E 17 St & Broadway 15747 Subscriber 1996
#> 4 South St & Whitehall St 23933 Subscriber 1963
#> 5 W 25 St & 6 Ave 23144 Subscriber 1988
#> start station location.type start station location.coordinates
#> 1 Point -74.00177, 40.75066
#> 2 Point -73.97137, 40.78275
#> 3 Point -73.99973, 40.71911
#> 4 Point -73.97606, 40.74402
#> 5 Point -73.99839, 40.75007
#> end station location.type end station location.coordinates
#> 1 Point -74.00264, 40.73902
#> 2 Point -74.00197, 40.74550
#> 3 Point -73.99009, 40.73705
#> 4 Point -74.01234, 40.70122
#> 5 Point -73.99145, 40.74395
#> start time stop time
#> 1 2016-01-01 02:00:48 2016-01-01 02:10:37
#> 2 2016-01-01 02:04:43 2016-01-01 02:34:14
#> 3 2016-01-01 02:02:18 2016-01-01 02:13:53
#> 4 2016-01-01 02:03:12 2016-01-01 02:26:09
#> 5 2016-01-01 02:10:29 2016-01-01 02:15:09Find a Document by Using the
$andOperator Use the$andoperator to use multiple$orexpressions in your query.
db.routes.find({
$and: [
{ $or: [{ dst_airport: "SEA" }, { src_airport: "SEA" }] },
{ $or: [{ "airline.name": "American Airlines" }, { airplane: 320 }] },
]
})Updating MongoDB Documents by Using findAndModify()
The findAndModify() method is used to find and replace a single document in MongoDB. It accepts a filter document, a replacement document, and an optional options object. The following code shows an example:
db.podcasts.findAndModify({
query: { _id: ObjectId("6261a92dfee1ff300dc80bf1") },
update: { $inc: { subscribers: 1 } },
new: true,
})updateMany()
Updating MongoDB Documents by Using updateMany() To update multiple documents, use the updateMany() method. This method accepts a filter document, an update document, and an optional options object. The following code shows an example:
db.books.updateMany( { publishedDate: { $lt: new Date("2019-01-01") } }, { $set: { status: "LEGACY" } } )Deleting Documents in MongoDB
To delete documents, use the deleteOne() or deleteMany() methods. Both methods accept a filter document and an options object.
Delete One Document The following code shows an example of the deleteOne() method:
db.podcasts.deleteOne({_id: Objectid("6282c9862acb966e76bbf20a") }) Delete Many Documents The following code shows an example of the deleteMany() method:
db.podcasts.deleteMany({category: "crime"})Sorting and Limiting Query Results in MongoDB
Review the following code, which demonstrates how to sort and limit query results.
Sorting Results
Use cursor.sort() to return query results in a specified order. Within the parentheses of sort(), include an object that specifies the field(s) to sort by and the order of the sort. Use 1 for ascending order, and -1 for descending order.
Syntax:
db.collection.find(<query>).sort(<sort>)Example:
// Return data on all music companies, sorted alphabetically from A to Z.
db.companies.find({ category_code: "music" }).sort({ name: 1 })To ensure documents are returned in a consistent order, include a field that contains unique values in the sort. An easy way to do this is to include the _id field in the sort. Here’s an example:
// Return data on all music companies, sorted alphabetically from A to Z. Ensure consistent sort order
db.companies.find({ category_code: "music" }).sort({ name: 1, _id: 1 })Limiting Results
Use cursor.limit() to specify the maximum number of documents the cursor will return. Within the parentheses of limit(), specify the maximum number of documents to return.
Syntax:
db.companies.find(<query>).limit(<number>)Example:
// Return the three music companies with the highest number of employees. Ensure consistent sort order.
db.companies
.find({ category_code: "music" })
.sort({ number_of_employees: -1, _id: 1 })
.limit(3)Descending Order in R
trips_collection$find(sort = '{"tripduration" : -1}' , limit = 5, fields = '{"_id" : true, "tripduration" : true}')
#> _id tripduration
#> 1 572bb8222b288919b68ac07c 326222
#> 2 572bb8232b288919b68b0f0d 279620
#> 3 572bb8232b288919b68b0593 173357
#> 4 572bb8232b288919b68ae9ee 152023
#> 5 572bb8222b288919b68ac1f0 146099Ascending Order in R
trips_collection$find(sort = '{"tripduration" : 1}' , limit = 5, fields = '{"_id" : true, "tripduration" : true}')
#> _id tripduration
#> 1 572bb8232b288919b68aef63 61
#> 2 572bb8222b288919b68ac2d4 61
#> 3 572bb8222b288919b68acefe 65
#> 4 572bb8232b288919b68afd2a 66
#> 5 572bb8232b288919b68af7cd 66Replacing a Document in MongoDB
To replace documents in MongoDB, we use the replaceOne() method. The replaceOne() method takes the following parameters:
-
filter:A query that matches the document to replace. -
replacement:The new document to replace the old one with. -
options:An object that specifies options for the update. In the previous video, we use the _id field to filter the document. In our replacement document, we provide the entire document that should be inserted in its place. Here’s the example code
db.books.replaceOne(
{
_id: ObjectId("6282afeb441a74a98dbbec4e"),
},
{
title: "Data Science Fundamentals for Python and MongoDB",
isbn: "1484235967",
publishedDate: new Date("2018-5-10"),
thumbnailUrl:
"https://m.media-amazon.com/images/I/71opmUBc2wL._AC_UY218_.jpg",
authors: ["David Paper"],
categories: ["Data Science"],
}
)Updating MongoDB Documents by Using updateOne()
The updateOne() method accepts a filter document, an update document, and an optional options object. MongoDB provides update operators and options to help you update documents. In this section, we’ll cover three of them: $set, upsert, and $push.
$set The $set operator replaces the value of a field with the specified value, as shown in the following code:
db.podcasts.updateOne(
{
_id: ObjectId("5e8f8f8f8f8f8f8f8f8f8f8"),
},
{
$set: {
subscribers: 98562,
},
}
)upsert The upsert option creates a new document if no documents match the filtered criteria. Here’s an example:
db.podcasts.updateOne(
{ title: "The Developer Hub" },
{ $set: { topics: ["databases", "MongoDB"] } },
{ upsert: true }
)$push The $push operator adds a new value to the hosts array field. Here’s an example:
db.podcasts.updateOne(
{ _id: ObjectId("5e8f8f8f8f8f8f8f8f8f8f8") },
{ $push: { hosts: "Nic Raboy" } }
)Updating MongoDB Documents by Using findAndModify()
The findAndModify() method is used to find and replace a single document in MongoDB. It accepts a filter document, a replacement document, and an optional options object. The following code shows an example:
db.podcasts.findAndModify({
query: { _id: ObjectId("6261a92dfee1ff300dc80bf1") },
update: { $inc: { subscribers: 1 } },
new: true,
})Updating MongoDB Documents by Using updateMany()
To update multiple documents, use the updateMany() method. This method accepts a filter document, an update document, and an optional options object. The following code shows an example:
db.books.updateMany(
{ publishedDate: { $lt: new Date("2019-01-01") } },
{ $set: { status: "LEGACY" } }
)Deleting Documents in MongoDB
To delete documents, use the deleteOne() or deleteMany() methods. Both methods accept a filter document and an options object.
Delete One Document The following code shows an example of the deleteOne() method:
db.podcasts.deleteOne({ _id: Objectid("6282c9862acb966e76bbf20a") })Delete Many Documents The following code shows an example of the deleteMany() method:
db.podcasts.deleteMany({category: “crime”})Returning Specific Data from a Query in MongoDB
Review the following code, which demonstrates how to return selected fields from a query.
Add a Projection Document
To specify fields to include or exclude in the result set, add a projection document as the second parameter in the call to db.collection.find().
Syntax:
db.collection.find( <query>, <projection> )Include a Field To include a field, set its value to 1 in the projection document.
Syntax:
db.collection.find( <query>, { <field> : 1 })Example:
// Return all restaurant inspections - business name, result, and _id fields only
db.inspections.find(
{ sector: "Restaurant - 818" },
{ business_name: 1, result: 1 }
)Exclude a Field To exclude a field, set its value to 0 in the projection document.
Syntax:
db.collection.find(query, { <field> : 0, <field>: 0 })Example:
// Return all inspections with result of “Pass” or “Warning” - exclude date and zip code
db.inspections.find(
{ result: { $in: ["Pass", "Warning"] } },
{ date: 0, "address.zip": 0 }
)While the _id field is included by default, it can be suppressed by setting its value to 0 in any projection.
// Return all restaurant inspections - business name and result fields only
db.inspections.find(
{ sector: "Restaurant - 818" },
{ business_name: 1, result: 1, _id: 0 }
)Counting Documents in a MongoDB Collection
Count Documents Use db.collection.countDocuments() to count the number of documents that match a query. countDocuments() takes two parameters: a query document and an options document.
Syntax:
db.collection.countDocuments( <query>, <options> )The query selects the documents to be counted.
Examples:
// Count number of docs in trip collection
db.trips.countDocuments({})
// Count number of trips over 120 minutes by subscribers
db.trips.countDocuments({ tripduration: { $gt: 120 }, usertype: "Subscriber" })MongoDB Aggregation
Definitions Aggregation: Collection and summary of data
Stage: One of the built-in methods that can be completed on the data, but does not permanently alter it
Aggregation pipeline: A series of stages completed on the data in order
Structure of an Aggregation Pipeline
db.collection.aggregate([
{
$stage1: {
{ expression1 },
{ expression2 }...
},
$stage2: {
{ expression1 }...
}
}
])Using $match and $group Stages in a MongoDB Aggregation Pipeline Review the following sections, which show the code for the $match and $group aggregation stages.
$match The $match stage filters for documents that match specified conditions. Here’s the code for $match:
{
$match: {
"field_name": "value"
}
}$group The $group stage groups documents by a group key.
{
$group:
{
_id: <expression>, // Group key
<field>: { <accumulator> : <expression> }
}
}
$match and $group in an Aggregation Pipeline
The following aggregation pipeline finds the documents with a field named “state” that matches a value “CA” and then groups those documents by the group key “$city” and shows the total number of zip codes in the state of California.
db.zips.aggregate([
{
$match: {
state: "CA"
}
},
{
$group: {
_id: "$city",
totalZips: { $count : { } }
}
}
])Using $sort and $limit Stages in a MongoDB Aggregation Pipeline
Review the following sections, which show the code for the $sort and $limit aggregation stages.
$sort The $sort stage sorts all input documents and returns them to the pipeline in sorted order. We use 1 to represent ascending order, and -1 to represent descending order.
{
$sort: {
"field_name": 1
}
}$limit The $limit stage returns only a specified number of records.
{
$limit: 5
}
$sort and $limit in an Aggregation Pipeline
The following aggregation pipeline sorts the documents in descending order, so the documents with the greatest pop value appear first, and limits the output to only the first five documents after sorting.
db.zips.aggregate([
{
$sort: {
pop: -1
}
},
{
$limit: 5
}
])Using $project, $count, and $set Stages in a MongoDB Aggregation Pipeline
$project The $project stage specifies the fields of the output documents. 1 means that the field should be included, and 0 means that the field should be supressed. The field can also be assigned a new value.
{
$project: {
state:1,
zip:1,
population:"$pop",
_id:0
}
}$set The $set stage creates new fields or changes the value of existing fields, and then outputs the documents with the new fields.
{
$set: {
place: {
$concat:["$city",",","$state"]
},
pop:10000
}
}$count
The $count stage creates a new document, with the number of documents at that stage in the aggregation pipeline assigned to the specified field name.
{
$count: "total_zips"
}