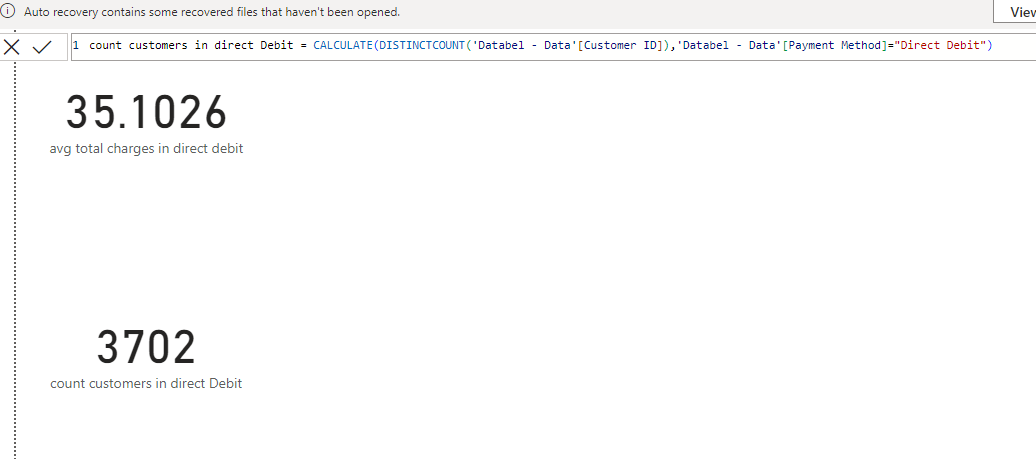
library(tidyverse)
churn<-readr::read_csv("Databel_Data.csv")
churn |>
head(10) |>
flextable::flextable()Customer ID |
Churn Label |
Account Length (in months) |
Local Calls |
Local Mins |
Intl Calls |
Intl Mins |
Intl Active |
Intl Plan |
Extra International Charges |
Customer Service Calls |
Avg Monthly GB Download |
Unlimited Data Plan |
Extra Data Charges |
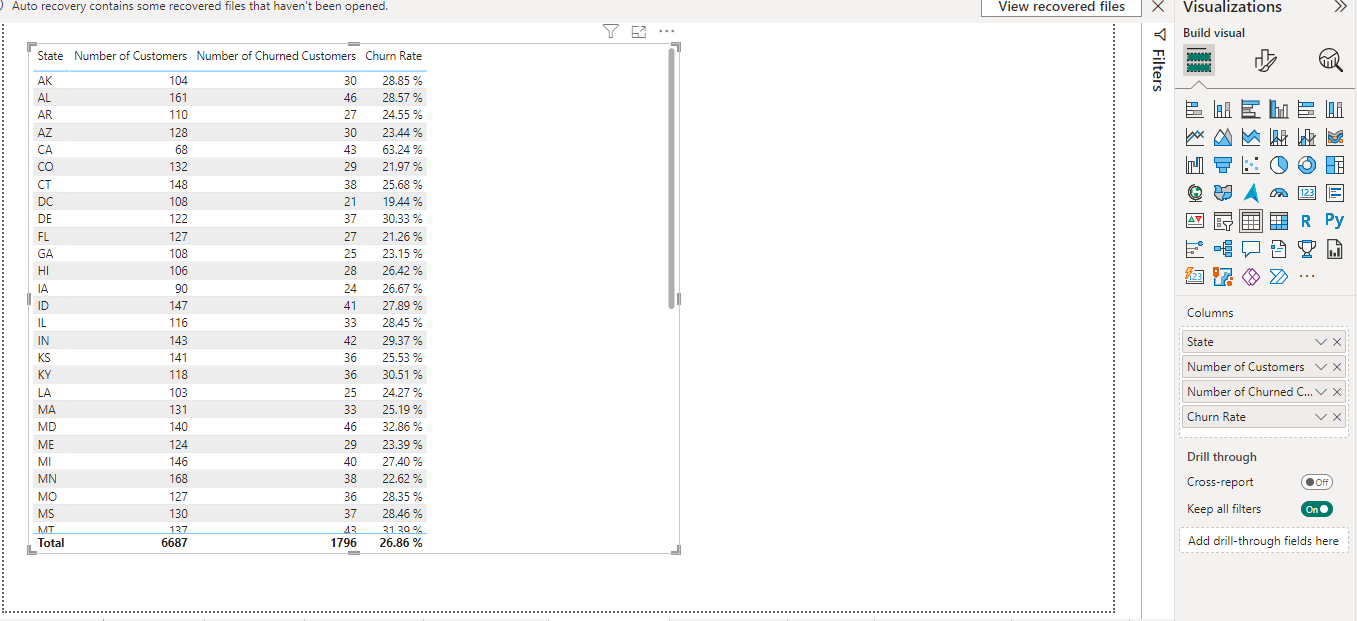
State |
Phone Number |
Gender |
Age |
Under 30 |
Senior |
Group |
Number of Customers in Group |
Device Protection & Online Backup |
Contract Type |
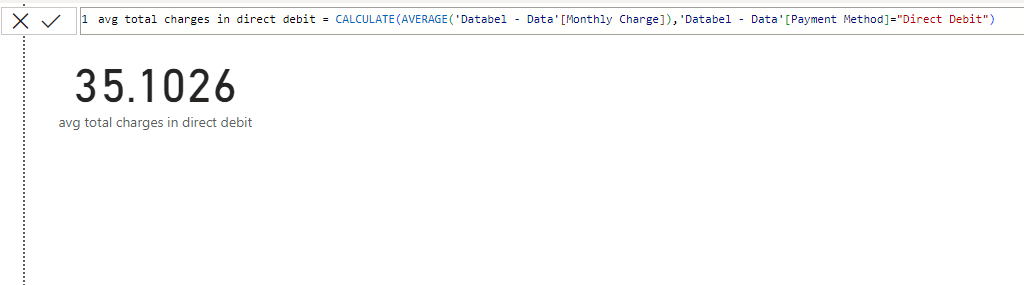
Payment Method |
Monthly Charge |
Total Charges |
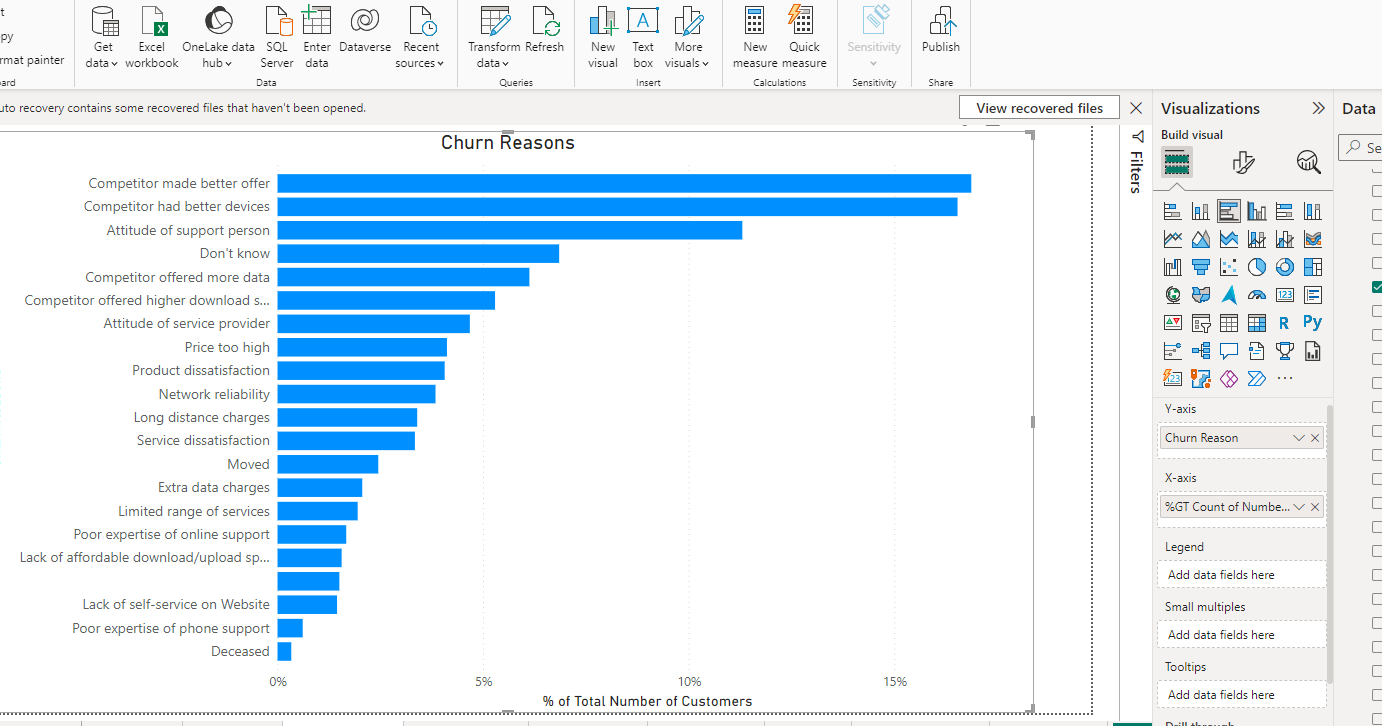
Churn Category |
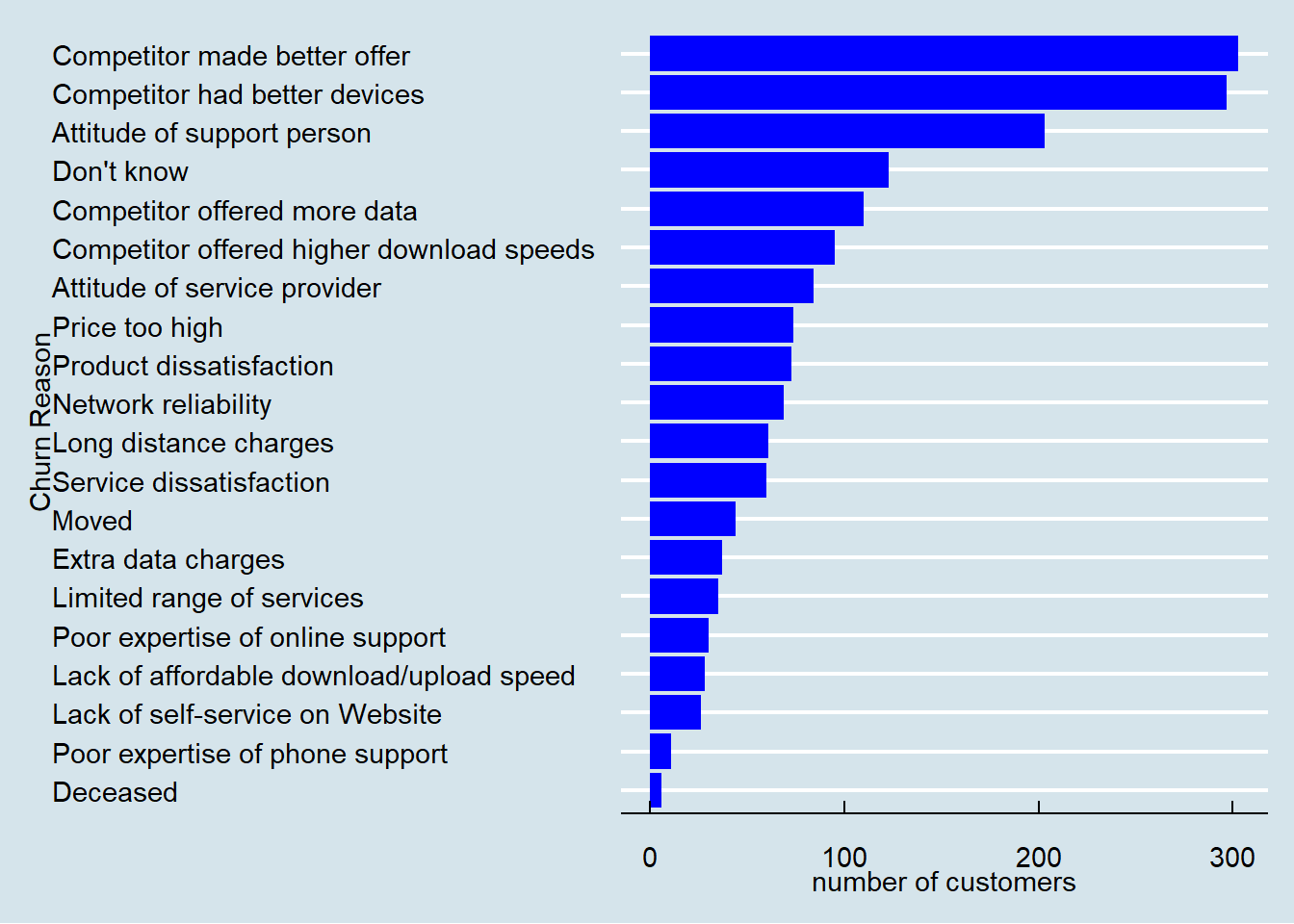
Churn Reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4444-BZPU |
No |
1 |
3 |
8.0 |
0 |
0.0 |
No |
no |
0 |
0 |
3 |
Yes |
0 |
KS |
382-4657 |
Female |
35 |
No |
No |
No |
0 |
No |
Month-to-Month |
Direct Debit |
10 |
10 |
||
5676-PTZX |
No |
33 |
179 |
431.3 |
0 |
0.0 |
No |
no |
0 |
0 |
3 |
Yes |
0 |
OH |
371-7191 |
Male |
49 |
No |
No |
No |
0 |
Yes |
One Year |
Paper Check |
21 |
703 |
||
8532-ZEKQ |
No |
44 |
82 |
217.6 |
0 |
0.0 |
No |
yes |
0 |
0 |
3 |
Yes |
0 |
OH |
375-9999 |
Male |
51 |
No |
No |
No |
0 |
Yes |
One Year |
Direct Debit |
23 |
1,014 |
||
1314-SMPJ |
No |
10 |
47 |
111.6 |
60 |
71.0 |
Yes |
yes |
0 |
0 |
2 |
Yes |
0 |
MO |
329-9001 |
Female |
41 |
No |
No |
No |
0 |
No |
Month-to-Month |
Paper Check |
17 |
177 |
||
2956-TXCJ |
No |
62 |
184 |
621.2 |
310 |
694.4 |
Yes |
yes |
0 |
0 |
3 |
Yes |
0 |
WV |
330-8173 |
Male |
51 |
No |
No |
No |
0 |
No |
One Year |
Direct Debit |
28 |
1,720 |
||
9152-DEPY |
No |
17 |
68 |
120.7 |
0 |
0.0 |
No |
no |
0 |
0 |
0 |
No |
0 |
RI |
344-9403 |
Male |
23 |
Yes |
No |
No |
0 |
No |
Two Year |
Credit Card |
9 |
156 |
||
1958-SDSO |
No |
57 |
428 |
849.2 |
0 |
0.0 |
No |
no |
0 |
0 |
5 |
Yes |
0 |
IA |
363-1107 |
Male |
38 |
No |
No |
No |
0 |
Yes |
One Year |
Credit Card |
47 |
2,671 |
||
8787-QZUC |
No |
25 |
54 |
203.7 |
0 |
0.0 |
No |
no |
0 |
0 |
12 |
Yes |
0 |
IA |
366-9238 |
Male |
29 |
Yes |
No |
No |
0 |
Yes |
Month-to-Month |
Direct Debit |
47 |
1,197 |
||
7768-OQJE |
No |
70 |
171 |
627.4 |
0 |
0.0 |
No |
no |
0 |
0 |
1 |
Yes |
0 |
NY |
351-7269 |
Female |
47 |
No |
No |
No |
0 |
Yes |
Two Year |
Credit Card |
52 |
3,593 |
||
7716-RHEB |
No |
50 |
206 |
445.8 |
0 |
0.0 |
No |
no |
0 |
0 |
0 |
No |
0 |
ID |
350-8884 |
Female |
61 |
No |
No |
No |
0 |
No |
One Year |
Paper Check |
11 |
539 |