Intermediate SQL
Data Science for Everyone
Limiting number of rows.
-
LIMIT nlimits how many rows we return
Find the first 10 rows in the
jobstable
SELECT *
FROM ____
LIMIT 10;Find the first 10 rows in the
employeestable
SELECT *
FROM ___
LIMIT ___;
CASE statements
CASE WHENx = 1THEN‘a’WHENx = 2THEN‘b’ELSE‘c’END ASnew_column
create a new column from the employee table such that if salary is
less than10000 it is categorized asless_10000, if it isbetween 10000 and 30000then it is categorised as10000_30000otherwise it is categorized asabove_30000and call the columnsalary_range.select
salaryas well
SELECT salary ,
CASE WHEN salary < '___' THEN '___'
WHEN salary BETWEEN '___' AND '___' THEN '10000_30000'
ELSE 'above_30000'
END AS '___'
FROM employees;
Grouping and Aggregating
- allows you to aggregate data based on a certain grouping
Find the
MIN()OF salary per eachjob_idthen per eachdepartment_idfrom the employees department ALIASE asmin_salary
SELECT job_id , MIN(__)
FROM employees
GROUP BY job_id;Find the
MAX()OF salary per eachjob_idthen per eachdepartment_idfrom the employees department aliase asmax_salary
SELECT job_id , ___(__) AS ___
FROM employees
GROUP BY ___;now do it for each
department_id
SELECT department_id, ___(__)
FROM employees
GROUP BY ___;SELECT department_id , ___(__)
FROM employees
GROUP BY ___;Find the
AVG()OF salary per eachjob_idthen per eachdepartment_idfrom the employees department
SELECT department_id , AVG(__) AS avg_salary
FROM ___
GROUP BY ___;Use
COUNT(*)to find number of employees in each departmentdepartment_id.
SELECT department_id ,COUNT(*) AS num_employees
FROM ___
GROUP BY ___;
Querying A join
generally the following step show how a join is done in SQL
-
SELECTt1.comon_column1,t1.common_column2,… -
FROMtable1ASt1 -
<type> JOINtable2ASt2 -
ONt1.common_unique_column = t2.common_unique_column;
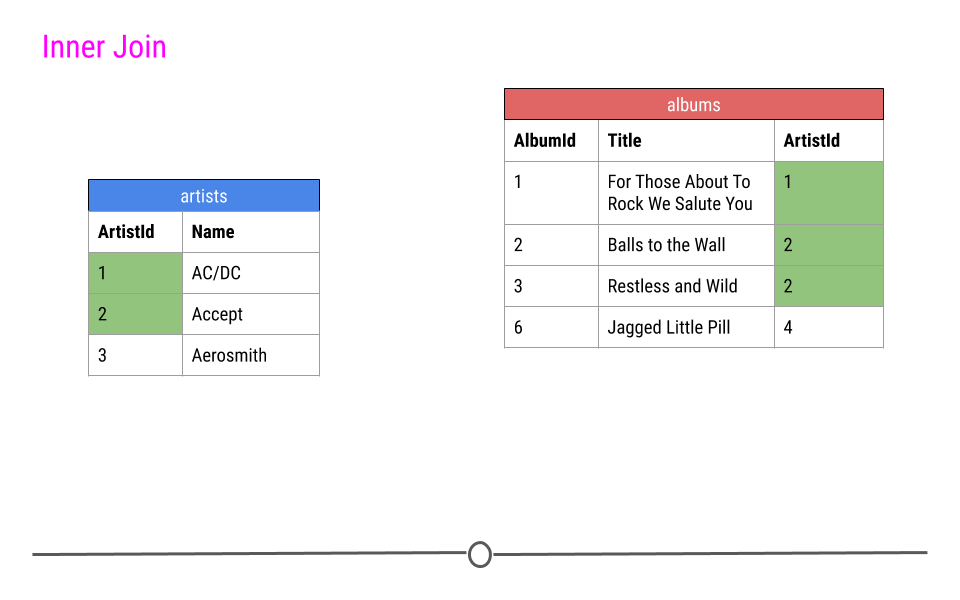
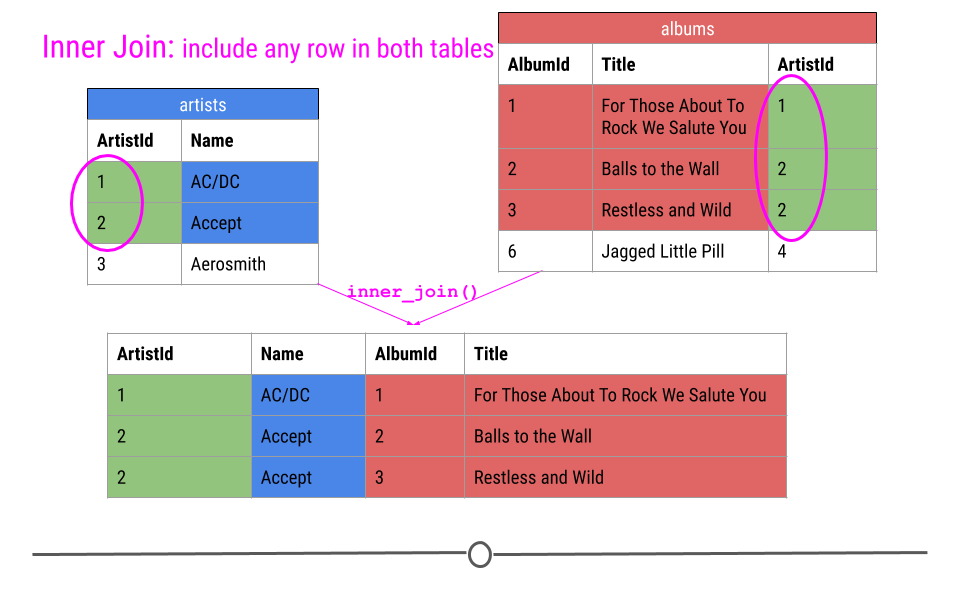
Inner Join
When talking about inner joins, we are only going to keep an observation if it is found in all of the tables we’re combining. Here, we’re combining the tables based on the ArtistId column. In our dummy example, there are only two artists that are found in both tables. These are highlighted in green and will be the rows used to join the two tables. Then, once the inner join happens, only these artists’ data will be included after the inner join.
when doing an inner join, data from any observation found in all the tables being joined are included in the output. Here, ArtistIds “1” and “2” are in both the artists and albums tables. Thus, those will be the only ArtistIds in the output from the inner join.
SELECT *
FROM employees
INNER JOIN jobs
USING(job_id)we note from the above that only
the coloursthat arecommon to both tablesare returned. however instead of usingUSINGwe can useON table1.columnname=table2.columnnamewherecolumnnameis the column that tables to be matched by and in our example this is columnjob_id. when using this method it is important to give each table anALIASwhich is ashorthandfor our tables
SELECT *
FROM ___ AS emp
___ JOIN ___ AS jo
ON emp.___=jo.____;
Window functions
- A window function performs an aggregate-like operation on a set of query rows.
However, whereas an aggregate operation groups query rows into a single result row, a window function produces a result for each query row:
Anatomy of a window function
FUNCTION_NAME() OVER()ORDER BYPARTITION BYROWS/RANGE PRECEDING/FOLLOWING/UNBOUNDED
Lets get started
- The row for which function evaluation occurs is called the current row.
- The query rows related to the current row over which function evaluation occurs comprise the window for the current row.
ROW_NUMBER() OVER()
- use it if maybe you have duplicates or intend to create rowids for your data
SELECT ROW_NUMBER() OVER () AS row_id ,first_name, last_name,email, salary
FROM employees;
PARTITION BY
- This splits the table into
partitionsbased on a column’s unique values and results aren’t rolled into one column
therefore
ROW_NUMBER()WithPARTITION BYproduces the row number of each row within its partition. In this case, rows are numbered per country. By default, partition rows are unordered and row numbering is nondeterministic.
SELECT ROW_NUMBER() OVER(PARTITION BY ____) AS row_num1, salary, job_id,
first_name, last_name,email
FROM _____ ;
RANK()
- ROW_NUMBER assigns different numbers to profits with the same amount, so it’s not a useful ranking function; if profits are the same , they should have the same rank.
in such a case we use
RANK()
rank by salary
SELECT RANK() OVER(ORDER BY ____ DESC) AS RANK,
first_name, last_name,email, salary
FROM employees;DENSE_RANK()
we can use
DENSE_RANK()if we need ranks to be ordered or require a further partition
SELECT DENSE_RANK() OVER(PARTITION BY __ ORDER BY __ DESC) AS RANK, job_id,salary
first_name, last_name,email
FROM employees;now we have ranked our salary by job starting with the highest salary for each job
Aggregations
- window functions are similar to
GROUP BYaggregate function but all rows stay in the output
using the employees information table, these two queries perform aggregate operations that produce a single global average for all rows taken as a group, and averages grouped per job:
SELECT AVG(___) AS avg_salary
FROM ____;lets us see a
GROUP BYin action
SELECT job_id, AVG(___) AS avg_salary
FROM employees
GROUP BY job_id;On the other hand , window operations do not collapse groups of query rows to a single output row. Instead, they produce a result for each row. Like the preceding queries, the following query uses
SUM(), but this time as a window function:
SELECT
first_name, last_name,email, salary,
AVG(__) OVER() AS avg_salary,
AVG(__) OVER(PARTITION BY ___) AS avg_per_job_salary
FROM ___
ORDER BY first_name, last_name,email, salary;
Note
we have included
OVERclause that specifies how to partition query rows into groups for processing by the window function:
- The first OVER clause is empty, which treats the entire set of query rows as a single partition. The window function thus produces a global sum, but does so for each row.
- The second OVER clause partitions rows by country, producing a sum per partition (per country). The function produces this sum for each partition row.
Window functions are permitted only in the select list and
ORDER BYclause. Query result rows are determined from theFROMclause, afterWHERE, GROUP BY, andHAVINGprocessing, and windowing execution occurs beforeORDER BY,LIMIT, andSELECT DISTINCT.